



Parler-TTS :一个完全开源的的高质量TTS模型
Parler-TTS 是一个由 Hugging Face 开发的轻量级文本转语音(TTS)模型,能够以给定说话者的风格(性别、音调、说话风格等)生成高质量、自然 sounding 的语音。它是基于 Dan Lyth 和 Simon King 发表的论文《Natural language guidance of high-fidelity text-to-speech with synthetic annotations》的工作复现,两位作者分别来自 Stability AI 和爱丁堡大学。
与其他TTS模型不同,Parler-TTS 完全开源发布,包括数据集、预处理、训练代码和权重。
● 高质量、自然 sounding 的语音输出:Parler-TTS 能够生成高质量且听起来非常自然的语音。它可以根据给定说话者的风格(如性别、音调、说话风格等)进行定制,以产生与特定人声非常相似的输出。
● 灵活的使用和部署:提供了易于使用的安装和部署方法,只需一行代码即可安装。此外,它还提供了交互式演示和详细的训练指南,使用户能够快速上手并自定义模型。
● Datasets数据集Parler-TTS 提供了开源的注释语音数据集,范围从1,000小时到即将到达的50,000小时。这为训练和改进TTS模型提供了丰富的资源。
GitHub:https://github.com/huggingface/parler-tts
模型下载:https://huggingface.co/parler-tts
在线体验:https://huggingface.co/spaces/parler-tts/parler_tts_mini
Parler-TTS 是一个由 Hugging Face 开发的轻量级文本转语音(TTS)模型,能够以给定说话者的风格(性别、音调、说话风格等)生成高质量、自然 sounding 的语音。它是基于 Dan Lyth 和 Simon King 发表的论文《Natural language guidance of high-fidelity text-to-speech with synthetic annotations》的工作复现,两位作者分别来自 Stability AI 和爱丁堡大学。
与其他TTS模型不同,Parler-TTS 完全开源发布,包括数据集、预处理、训练代码和权重。
● 高质量、自然 sounding 的语音输出:Parler-TTS 能够生成高质量且听起来非常自然的语音。它可以根据给定说话者的风格(如性别、音调、说话风格等)进行定制,以产生与特定人声非常相似的输出。
● 灵活的使用和部署:提供了易于使用的安装和部署方法,只需一行代码即可安装。此外,它还提供了交互式演示和详细的训练指南,使用户能够快速上手并自定义模型。
● Datasets数据集Parler-TTS 提供了开源的注释语音数据集,范围从1,000小时到即将到达的50,000小时。这为训练和改进TTS模型提供了丰富的资源。
GitHub:https://github.com/huggingface/parler-tts
模型下载:https://huggingface.co/parler-tts
在线体验:https://huggingface.co/spaces/parler-tts/parler_tts_mini
video-subtitle-remover 一款基于AI技术,将视频中的硬字幕去除的软件。
https://github.com/YaoFANGUK/video-subtitle-remover
- 无损分辨率将视频中的硬字幕去除,生成去除字幕后的文件
- 通过超强AI算法模型,对去除字幕文本的区域进行填充(非相邻像素填充与马赛克去除)
- 支持自定义字幕位置,仅去除定义位置中的字幕(传入位置)
- 支持全视频自动去除所有文本(不传入位置)
- 支持多选图片批量去除水印文本
https://github.com/YaoFANGUK/video-subtitle-remover
- 无损分辨率将视频中的硬字幕去除,生成去除字幕后的文件
- 通过超强AI算法模型,对去除字幕文本的区域进行填充(非相邻像素填充与马赛克去除)
- 支持自定义字幕位置,仅去除定义位置中的字幕(传入位置)
- 支持全视频自动去除所有文本(不传入位置)
- 支持多选图片批量去除水印文本
Harper-AI视频生成器
介绍
Harper是近期推出的一项AI生成视频服务,支持文本生成视频、图片制作动画、重绘视频等
官网:https://haiper.ai
使用比较简单,页面中可以找到输入框及功能说明,可以在左列中查看生成历史记录。
不同的模式可以带来不同的视频创造效果
使用前建议先查看首页中的视频提示词
介绍
Harper是近期推出的一项AI生成视频服务,支持文本生成视频、图片制作动画、重绘视频等
官网:https://haiper.ai
使用比较简单,页面中可以找到输入框及功能说明,可以在左列中查看生成历史记录。
不同的模式可以带来不同的视频创造效果
使用前建议先查看首页中的视频提示词
🎵 Text 2 music 重量级新玩家 Udio 隆重登场~
Udio 是一款用于音乐创作和共享的应用程序,通过直观、强大的文本提示功能,你可以用自己喜欢的风格创作出令人惊叹的音乐。由前 Google DeepMind 的顶尖 AI 研究人员和工程师创立。
用任何风格的富有表现力的人声让你的歌词栩栩如生。从高亢的福音到沙哑的布鲁斯,从梦幻的流行乐到柔滑的说唱,Udio 应有尽有。
探索非凡的流派和风格范围。有劲爆的 EDM、摇摆的钢琴爵士乐、温和的新灵魂乐和极端金属乐。Udio 的目标是成为音乐人和非音乐人的革命性工具,V1 模型功能强大,但并不完美。
目前 Udio 是一个免费的测试版产品, 每个人每月可以生成多达1200 首歌曲。
🔗不妨试试看:https://www.udio.com
Udio 是一款用于音乐创作和共享的应用程序,通过直观、强大的文本提示功能,你可以用自己喜欢的风格创作出令人惊叹的音乐。由前 Google DeepMind 的顶尖 AI 研究人员和工程师创立。
用任何风格的富有表现力的人声让你的歌词栩栩如生。从高亢的福音到沙哑的布鲁斯,从梦幻的流行乐到柔滑的说唱,Udio 应有尽有。
探索非凡的流派和风格范围。有劲爆的 EDM、摇摆的钢琴爵士乐、温和的新灵魂乐和极端金属乐。Udio 的目标是成为音乐人和非音乐人的革命性工具,V1 模型功能强大,但并不完美。
目前 Udio 是一个免费的测试版产品, 每个人每月可以生成多达1200 首歌曲。
🔗不妨试试看:https://www.udio.com

🆔 项目名称:MoneyPrinterTurbo
⭐️ 项目功能:AI 视频
📁 项目简介:一款可以一键生成AI短视频的开源项目。只需提供一个视频主题或关键词,就可以全自动地生成视频文案、视频素材、视频字幕、视频背景音乐,并最终合成一个高清的短视频。
支持多种高清视频尺寸、批量视频生成、视频片段时长设置、中英文视频文案、多种语音合成、字幕生成、背景音乐,且视频素材高清无版权。
还支持OpenAI、moonshot、Azure、gpt4free、one-api、通义千问、Google Gemini、Ollama等多种模型接入。
https://github.com/harry0703/MoneyPrinterTurbo
⭐️ 项目功能:AI 视频
📁 项目简介:一款可以一键生成AI短视频的开源项目。只需提供一个视频主题或关键词,就可以全自动地生成视频文案、视频素材、视频字幕、视频背景音乐,并最终合成一个高清的短视频。
支持多种高清视频尺寸、批量视频生成、视频片段时长设置、中英文视频文案、多种语音合成、字幕生成、背景音乐,且视频素材高清无版权。
还支持OpenAI、moonshot、Azure、gpt4free、one-api、通义千问、Google Gemini、Ollama等多种模型接入。
https://github.com/harry0703/MoneyPrinterTurbo
🔥整理了一下我公开发表过的prompt:
🍠1. 小红书爬虫数据分析(用浏览器插件爬取小红书笔记数据,生成excel表格以后丢给大模型分析,作为文科生,不懂数据清洗和什么向量数据之类的,这是我能想到的数据分析的方法🤣)
🔗链接:https://web.okjike.com/originalPost/66062d91de5f2873487edd65
🍠2. 小红书笔记创作(这个是我尝试让小红书创作文案的第一个尝试,不过效果一般,不能期待大模型有太个性化的输出,文案还要自己写)
🔗链接:https://web.okjike.com/originalPost/65bb686337f7165b21a6d4dc
📚3. 渐进式阅读助手(这条上了即刻小镇日报,是我没想到的,本来我是用在Obsidian里面做笔记用的。格式相对比较乱😭,需要自己再根据自己需求调整)
🔗链接:https://web.okjike.com/originalPost/65d819fa38849f879fe722cf
📒4. 文章总结(简单易用,适合用来总结含有案例,数据的文章)
🔗链接:https://web.okjike.com/originalPost/658cd1f23af12f55ba7d8973
🏷5. 公众号文章阅读(我主要用来萃取公众号文章的重点内容,包含元数据,自动生成相应标签,识别关键术语,便于做笔记)
🔗链接:https://web.okjike.com/originalPost/65b2097f3b9c66cae4c786cc
👨🏫6. 法考助手(做了一个专门解答法考教材里的问题的prompt,辅助法考学习,用在Gemini 1.5 pro里面)
🔗链接:https://web.okjike.com/originalPost/660bb46537f7165b2198d170
🤖7. 文章萃取筛选机器人(我在coze上自己搓了一个bot,使用频率最高,我放在dicord里面用,我的需求是把躺在稍后读列表里面的文章链接丢给他,萃取关键信息+有价值的见解,然后我再决定是否继续阅读,累计有300人使用)
🔗链接:https://www.coze.com/store/bot/7334310207146721285?panel=1&bid=MDQEEEiFix85U2v0MQbWUFWqukEEHvQDnQaBvM9xqLWc2YsBTAbPTUuXKayACGHlTeeqmwQA&share=1&from=others
🏠8. COSTAR框架提示词生成助手(用来生成提示词)
🔗链接:https://web.okjike.com/originalPost/65bc6687a922aa28d0c28961
🍠1. 小红书爬虫数据分析(用浏览器插件爬取小红书笔记数据,生成excel表格以后丢给大模型分析,作为文科生,不懂数据清洗和什么向量数据之类的,这是我能想到的数据分析的方法🤣)
🔗链接:https://web.okjike.com/originalPost/66062d91de5f2873487edd65
🍠2. 小红书笔记创作(这个是我尝试让小红书创作文案的第一个尝试,不过效果一般,不能期待大模型有太个性化的输出,文案还要自己写)
🔗链接:https://web.okjike.com/originalPost/65bb686337f7165b21a6d4dc
📚3. 渐进式阅读助手(这条上了即刻小镇日报,是我没想到的,本来我是用在Obsidian里面做笔记用的。格式相对比较乱😭,需要自己再根据自己需求调整)
🔗链接:https://web.okjike.com/originalPost/65d819fa38849f879fe722cf
📒4. 文章总结(简单易用,适合用来总结含有案例,数据的文章)
🔗链接:https://web.okjike.com/originalPost/658cd1f23af12f55ba7d8973
🏷5. 公众号文章阅读(我主要用来萃取公众号文章的重点内容,包含元数据,自动生成相应标签,识别关键术语,便于做笔记)
🔗链接:https://web.okjike.com/originalPost/65b2097f3b9c66cae4c786cc
👨🏫6. 法考助手(做了一个专门解答法考教材里的问题的prompt,辅助法考学习,用在Gemini 1.5 pro里面)
🔗链接:https://web.okjike.com/originalPost/660bb46537f7165b2198d170
🤖7. 文章萃取筛选机器人(我在coze上自己搓了一个bot,使用频率最高,我放在dicord里面用,我的需求是把躺在稍后读列表里面的文章链接丢给他,萃取关键信息+有价值的见解,然后我再决定是否继续阅读,累计有300人使用)
🔗链接:https://www.coze.com/store/bot/7334310207146721285?panel=1&bid=MDQEEEiFix85U2v0MQbWUFWqukEEHvQDnQaBvM9xqLWc2YsBTAbPTUuXKayACGHlTeeqmwQA&share=1&from=others
🏠8. COSTAR框架提示词生成助手(用来生成提示词)
🔗链接:https://web.okjike.com/originalPost/65bc6687a922aa28d0c28961
gpt-prompt-engineer
帮助你生成、优化和测试 Prompt,支持GPT和Claude,并且可以优化 Claude 3 Haiku 的提示词,帮助达到很好的效果。值得一提的是, Claude 3 Haiku 价格比 GPT-3.5 还便宜,但是性能不错,并且支持视觉模型。
https://github.com/mshumer/gpt-prompt-engineer
帮助你生成、优化和测试 Prompt,支持GPT和Claude,并且可以优化 Claude 3 Haiku 的提示词,帮助达到很好的效果。值得一提的是, Claude 3 Haiku 价格比 GPT-3.5 还便宜,但是性能不错,并且支持视觉模型。
https://github.com/mshumer/gpt-prompt-engineer

emgithub
打开 GitHub 仓库某个文件的页面,将地址栏的 github.com 改成 emgithub.com,就可以获得当前文件的嵌入代码,像嵌入 GitHub Gist 代码一样嵌入到页面中。
https://github.com/yusanshi/emgithub
打开 GitHub 仓库某个文件的页面,将地址栏的 github.com 改成 emgithub.com,就可以获得当前文件的嵌入代码,像嵌入 GitHub Gist 代码一样嵌入到页面中。
https://github.com/yusanshi/emgithub
Easy Highlight - 自动高亮网页中的特定关键词
在任意网页上自动检测并高亮您的自定义列表中的多个单词和词组
Easy Highlight是一款自动化的Chrome扩展程序,能够在任何网页上轻松地对关键词进行高亮显示!使用我们的扩展程序,您可以轻松地高亮您感兴趣的关键词,非常适合各种用户,包括人力资源专业人员、学者、学生以及任何想要改善在线阅读体验的人士。您也可以高亮自己公司的名称和业务名,以便随时注意到相关的信息。
✔️功能:
1.轻松自动高亮:只需输入您想要高亮的任何关键词,我们的系统就会在您浏览网页时自动高亮它们。
2.可读性优先:我们的扩展程序的主要功能是为每个关键词自动生成背景颜色,遵循Web内容可访问性指南(版本1.0),以确保最大程度的可读性。再也不用担心由于颜色对比度问题而难以阅读的文字了。
3.区分大小写:我们提供了区分大小写的选项,这意味着扩展程序将正确匹配关键词,无论它们的大小写如何。因此,您可以放心,即使关键词与您输入的大小写不同,它们也会被高亮显示。
4.用户友好的设计:使用Easy Highlight非常容易!它被设计为超级用户友好和直观的。您不必担心复杂的设置或陡峭的学习曲线。
5.一键禁用:只需单击一下,您就可以轻松关闭高亮显示功能,无需担心它会影响您的浏览体验。
6.高亮单个单词或短语:Easy Highlight支持单个单词和短语的高亮。
😊如何使用:
1.输入您想要高亮的关键词或短语,然后按回车键。
2.要删除关键词,只需在扩展程序界面上单击它即可。
https://chromewebstore.google.com/detail/jdobpplllaoakelgogmmjnnpnaahnhjn?hl=zh-CN
在任意网页上自动检测并高亮您的自定义列表中的多个单词和词组
Easy Highlight是一款自动化的Chrome扩展程序,能够在任何网页上轻松地对关键词进行高亮显示!使用我们的扩展程序,您可以轻松地高亮您感兴趣的关键词,非常适合各种用户,包括人力资源专业人员、学者、学生以及任何想要改善在线阅读体验的人士。您也可以高亮自己公司的名称和业务名,以便随时注意到相关的信息。
✔️功能:
1.轻松自动高亮:只需输入您想要高亮的任何关键词,我们的系统就会在您浏览网页时自动高亮它们。
2.可读性优先:我们的扩展程序的主要功能是为每个关键词自动生成背景颜色,遵循Web内容可访问性指南(版本1.0),以确保最大程度的可读性。再也不用担心由于颜色对比度问题而难以阅读的文字了。
3.区分大小写:我们提供了区分大小写的选项,这意味着扩展程序将正确匹配关键词,无论它们的大小写如何。因此,您可以放心,即使关键词与您输入的大小写不同,它们也会被高亮显示。
4.用户友好的设计:使用Easy Highlight非常容易!它被设计为超级用户友好和直观的。您不必担心复杂的设置或陡峭的学习曲线。
5.一键禁用:只需单击一下,您就可以轻松关闭高亮显示功能,无需担心它会影响您的浏览体验。
6.高亮单个单词或短语:Easy Highlight支持单个单词和短语的高亮。
😊如何使用:
1.输入您想要高亮的关键词或短语,然后按回车键。
2.要删除关键词,只需在扩展程序界面上单击它即可。
https://chromewebstore.google.com/detail/jdobpplllaoakelgogmmjnnpnaahnhjn?hl=zh-CN
pagenote一页一记
在任意网页内,摘录重点、划线批注。打造个人笔记系统。
1、文本高亮
高亮网页里的关键内容。支持多种颜色,可锚点定位。
2、网页笔记
一页一记:把笔记留在网页里,不用单独在记事本存储。下次打开笔记自动出现。
3、智能书签
根据标记智能创建、删除书签。还可为网页添加标签,方便管理、查找。
4、网页快照
对网页进行快照保存。刻下当前访问内容,网页内容变了也能查看历史记录。
5、导入导出
支持备份、还原,还可导出多种格式:JSON、Markdown
让好友一眼就知道你的分享重点。可区分仅分享标记或分享整个网页。
7、个人主页
拥有自己的私人网页管理主页。管理你自己的知识星球。
8、不要求登录,用户自己掌握数据,可离线运行
https://chromewebstore.google.com/detail/hpekbddiphlmlfjebppjhemobaopekmp
在任意网页内,摘录重点、划线批注。打造个人笔记系统。
1、文本高亮
高亮网页里的关键内容。支持多种颜色,可锚点定位。
2、网页笔记
一页一记:把笔记留在网页里,不用单独在记事本存储。下次打开笔记自动出现。
3、智能书签
根据标记智能创建、删除书签。还可为网页添加标签,方便管理、查找。
4、网页快照
对网页进行快照保存。刻下当前访问内容,网页内容变了也能查看历史记录。
5、导入导出
支持备份、还原,还可导出多种格式:JSON、Markdown
让好友一眼就知道你的分享重点。可区分仅分享标记或分享整个网页。
7、个人主页
拥有自己的私人网页管理主页。管理你自己的知识星球。
8、不要求登录,用户自己掌握数据,可离线运行
https://chromewebstore.google.com/detail/hpekbddiphlmlfjebppjhemobaopekmp
nginx-proxy-manager
该项目是一个预构建的 Docker 镜像,可以让您轻松地将您在家中或其他地方运行的网站转发出去,包括免费 SSL,而无需对 Nginx 或 Letsencrypt 有太多了解。
https://github.com/NginxProxyManager/nginx-proxy-manager
该项目是一个预构建的 Docker 镜像,可以让您轻松地将您在家中或其他地方运行的网站转发出去,包括免费 SSL,而无需对 Nginx 或 Letsencrypt 有太多了解。
https://github.com/NginxProxyManager/nginx-proxy-manager

chatnio: 开源的一站式AI前端解决方案
这是一个开源的前端项目。AI 一站式解决方案,一站式 Chat + 中转 API 站点,支持 OpenAI,Midjourney,Claude,讯飞星火,Stable Diffusion,DALL·E,ChatGLM,通义千问,腾讯混元,360 智脑,百川 AI,火山方舟,新必应,Gemini,Moonshot 等模型,支持对话分享,自定义预设,云端同步,模型市场,支持弹性计费和订阅计划模式,支持图片解析,支持联网搜索,支持模型缓存,丰富美观的后台管理与仪表盘数据统计。
https://github.com/Deeptrain-Community/chatnio/blob/main/README_zh-CN.md
这是一个开源的前端项目。AI 一站式解决方案,一站式 Chat + 中转 API 站点,支持 OpenAI,Midjourney,Claude,讯飞星火,Stable Diffusion,DALL·E,ChatGLM,通义千问,腾讯混元,360 智脑,百川 AI,火山方舟,新必应,Gemini,Moonshot 等模型,支持对话分享,自定义预设,云端同步,模型市场,支持弹性计费和订阅计划模式,支持图片解析,支持联网搜索,支持模型缓存,丰富美观的后台管理与仪表盘数据统计。
https://github.com/Deeptrain-Community/chatnio/blob/main/README_zh-CN.md
VideoTrans视频翻译和配音
一键字幕识别+翻译+配音=带新语言字幕和配音的视频
【翻译视频并配音】根据需要设置各个选项,自由配置组合,实现翻译和配音、自动加减速、合并等
【识别字幕不翻译】选择视频文件,选择视频源语言,则从视频【语音中识别出文字】并自动导出字幕文件到目标文件夹
【提取字幕并翻译】选择视频文件,选择视频源语言,设置想翻译到的目标语言,则从【视频语音中识别出文字】并翻译为目标语言,然后导出双语字幕文件到目标文件夹
【字幕和视频合并】选择视频,然后将已有的字幕文件拖拽到右侧字幕区,将源语言和目标语言都设为字幕所用语言、然后选择配音类型和角色,开始执行
【为字幕创建配音】将本地的字幕文件拖拽到右侧字幕编辑器,然后选择目标语言、配音类型和角色,将生成配音后的音频文件到目标文件夹
【音视频识别文字】将视频或音频拖拽到识别窗口,将识别出文字并导出为srt字幕格式
【将文字合成语音】将一段文字或者字幕,使用指定的配音角色生成配音
【从视频分离音频】将视频文件分离为音频文件和无声视频
【音视频字幕合并】音频文件、视频文件、字幕文件合并为一个视频文件
【音视频格式转换】各种格式之间的相互转换
【文字字幕翻译】将文字或srt字幕文件翻译为其他语言
【人声背景乐分离】将视频中的人声和背景音乐分别分离出来,生成2个音频文件
【下载油管视频】可从youtube上下载视频
https://github.com/jianchang512/pyvideotrans
一键字幕识别+翻译+配音=带新语言字幕和配音的视频
【翻译视频并配音】根据需要设置各个选项,自由配置组合,实现翻译和配音、自动加减速、合并等
【识别字幕不翻译】选择视频文件,选择视频源语言,则从视频【语音中识别出文字】并自动导出字幕文件到目标文件夹
【提取字幕并翻译】选择视频文件,选择视频源语言,设置想翻译到的目标语言,则从【视频语音中识别出文字】并翻译为目标语言,然后导出双语字幕文件到目标文件夹
【字幕和视频合并】选择视频,然后将已有的字幕文件拖拽到右侧字幕区,将源语言和目标语言都设为字幕所用语言、然后选择配音类型和角色,开始执行
【为字幕创建配音】将本地的字幕文件拖拽到右侧字幕编辑器,然后选择目标语言、配音类型和角色,将生成配音后的音频文件到目标文件夹
【音视频识别文字】将视频或音频拖拽到识别窗口,将识别出文字并导出为srt字幕格式
【将文字合成语音】将一段文字或者字幕,使用指定的配音角色生成配音
【从视频分离音频】将视频文件分离为音频文件和无声视频
【音视频字幕合并】音频文件、视频文件、字幕文件合并为一个视频文件
【音视频格式转换】各种格式之间的相互转换
【文字字幕翻译】将文字或srt字幕文件翻译为其他语言
【人声背景乐分离】将视频中的人声和背景音乐分别分离出来,生成2个音频文件
【下载油管视频】可从youtube上下载视频
https://github.com/jianchang512/pyvideotrans
Open Assistant API 是一个开源自托管的 AI 智能助手 API,兼容 OpenAI 官方接口, 可以直接使用 OpenAI 官方的 Client 构建 LLM 应用。
支持 One API 可以用其接入更多商业和私有模型。
https://github.com/Tuanzi1015/open-assistant-api/blob/main/README_CN.md
支持 One API 可以用其接入更多商业和私有模型。
https://github.com/Tuanzi1015/open-assistant-api/blob/main/README_CN.md
Puter 概览 🌟
Puter 是一个**开源桌面环境**,它在浏览器中运行,提供了一系列丰富的功能。这个环境以其**速度快**和**高度可扩展**性著称,旨在为用户提供一个隐私保护的个人云服务。Puter 允许用户将文件、应用和游戏存储在一个安全的位置,随时随地都能访问。
**主要用途**:
1. **云存储服务**:作为 Dropbox、Google Drive、OneDrive 的高级替代品,Puter 提供了一个用户友好的界面和增强的功能。
2. **远程桌面环境**:适用于服务器和工作站,便于远程访问和管理。
3. **Web 开发平台**:可以用于构建和托管网站、Web 应用和游戏。
4. **学习社区**:Puter 还是一个开放的项目和社区,适合那些有兴趣学习 Web 开发、云计算和分布式系统等领域的人。
**资源链接**:
- GitHub 项目页:[HeyPuter/puter](https://github.com/HeyPuter/puter)
- 官方网站:[Puter.com](https://puter.com/)
- 开发文档:[Puter.js 文档](https://docs.puter.com/)
Puter 不仅仅是一个技术产品,它还致力于建立一个友好的开源社区,鼓励用户和开发者学习和分享新知。
Puter 是一个**开源桌面环境**,它在浏览器中运行,提供了一系列丰富的功能。这个环境以其**速度快**和**高度可扩展**性著称,旨在为用户提供一个隐私保护的个人云服务。Puter 允许用户将文件、应用和游戏存储在一个安全的位置,随时随地都能访问。
**主要用途**:
1. **云存储服务**:作为 Dropbox、Google Drive、OneDrive 的高级替代品,Puter 提供了一个用户友好的界面和增强的功能。
2. **远程桌面环境**:适用于服务器和工作站,便于远程访问和管理。
3. **Web 开发平台**:可以用于构建和托管网站、Web 应用和游戏。
4. **学习社区**:Puter 还是一个开放的项目和社区,适合那些有兴趣学习 Web 开发、云计算和分布式系统等领域的人。
**资源链接**:
- GitHub 项目页:[HeyPuter/puter](https://github.com/HeyPuter/puter)
- 官方网站:[Puter.com](https://puter.com/)
- 开发文档:[Puter.js 文档](https://docs.puter.com/)
Puter 不仅仅是一个技术产品,它还致力于建立一个友好的开源社区,鼓励用户和开发者学习和分享新知。
快手也发布了一个通过拖动锚点控制视频物体和镜头运动的项目DragAnything。
与现有的运动控制技术相比,DragAnything 有几个显着的优势:
首先,基于轨迹的操作方式对用户更友好,尤其是在获取其他辅助信号(如遮罩、深度图等)较为繁琐时。用户只需在互动中绘制一条线(即轨迹)即可。
其次,我们的实体识别技术能够处理任何对象,这意味着它可以控制包括背景在内的各种实体的运动。
最后,这种实体识别技术还可以同时对多个对象实现不同的运动控制。
大量实验表明,我们的技术在 FVD、FID 和用户体验研究方面均达到了行业领先水平,特别是在对象运动控制方面,我们的方法比之前的技术(例如 DragNUWA)在人类评估中提高了 26%。
项目地址:https://weijiawu.github.io/draganything_page/
与现有的运动控制技术相比,DragAnything 有几个显着的优势:
首先,基于轨迹的操作方式对用户更友好,尤其是在获取其他辅助信号(如遮罩、深度图等)较为繁琐时。用户只需在互动中绘制一条线(即轨迹)即可。
其次,我们的实体识别技术能够处理任何对象,这意味着它可以控制包括背景在内的各种实体的运动。
最后,这种实体识别技术还可以同时对多个对象实现不同的运动控制。
大量实验表明,我们的技术在 FVD、FID 和用户体验研究方面均达到了行业领先水平,特别是在对象运动控制方面,我们的方法比之前的技术(例如 DragNUWA)在人类评估中提高了 26%。
项目地址:https://weijiawu.github.io/draganything_page/
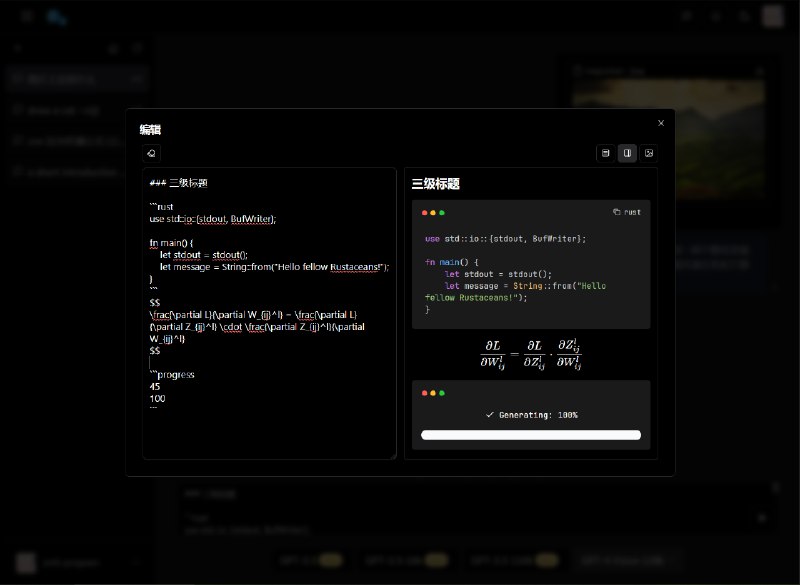
本文介绍了如何使用LLM IDE(Dify)快速搭建模型应用,并使用超长上下文的200K模型完成电子书翻译。作者通过准备工具、获取电子书、启动Dify IDE和配置零一万物模型等步骤,详细阐述了整个翻译过程。最后,作者提到配置模型翻译应用并开始进行翻译工作。整篇文章旨在为读者提供一个高效、便捷的电子书翻译方案。
https://soulteary.com/2024/03/13/use-yi-34b-chat-200k-model-and-dify-to-quickly-build-model-application.html
https://soulteary.com/2024/03/13/use-yi-34b-chat-200k-model-and-dify-to-quickly-build-model-application.html